DL05
DNN
Hidden Units
- 최적의 hidden layer의 노드의 개수를 정하기는 어렵다.
- activation function을 이용하여 output을 non-linear하게 만들어주어야 제대로 작동한다.
Activation Function
- ReLu : y(x) = max{0,x}
- Leaky ReLU : α가 0.01
- PReLu : α가 학습의 대상이다.
- Maxout unit : 임의의 직선들 중 더 큰 값을 출력하는 함수
- Logistic sigmoid, Hyperbolic tangent
Backpropagation
- 미분의 chain rule을 이용하여 계속해서 loss를 weight에 반영한다.
Regularization
- bias와 variance 사이의 trade-off가 존재한다.
- 큰 모델은 적절한 규제를 통하여 과적합을 막고 성능을 끌어올릴 수 있다.

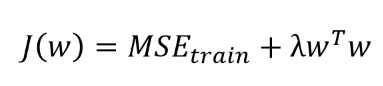
Parameter regularization
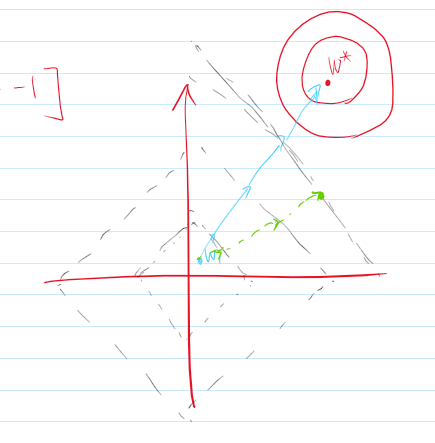
LASSO regression
- weight들 중 0의 비율을 높여서 node를 꺼버린다.
Ridge regression
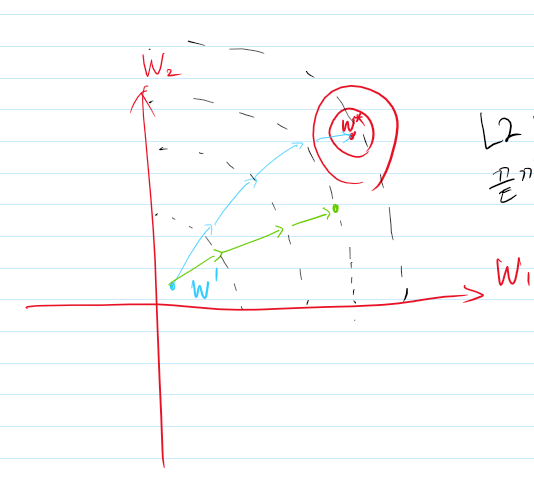
L2 parameter regularization
L1 parameter regularization
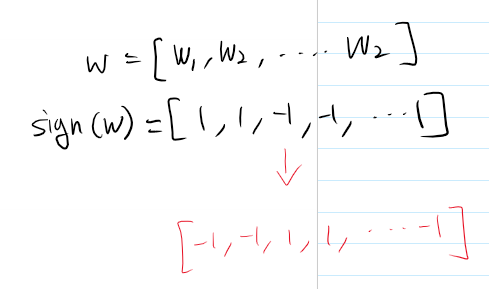
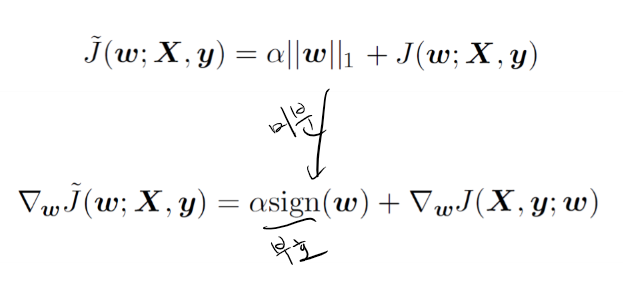
Dataset augmentation
- fake data를 적절히 섞어줌으로서 학습을 방해한다.
- object recognition, 샘플의 약간의 변화가 일반화 성능을 높일 수 있는 task, moving, rotating, scaling 등등
Noise robustness
- input data or hidden units or weights에 잡음을 섞어서 학습을 방해한다.
Multitask learning
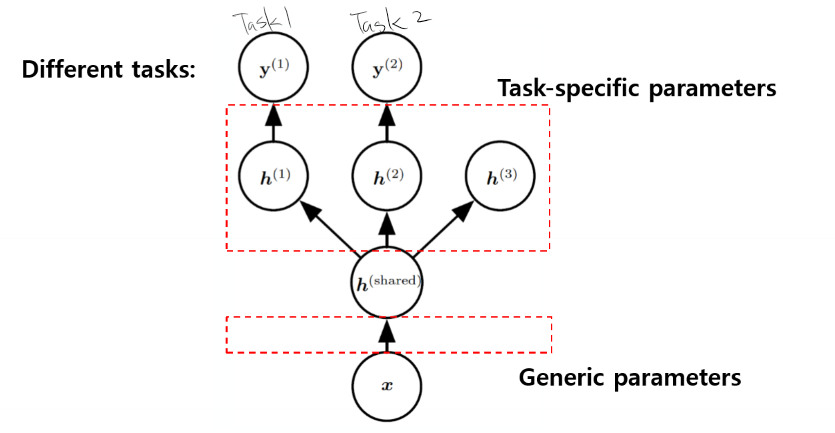
- 여러개의 task를 수행하는 학습을 같이하고 task층에 가까운 노드들은 각각의 task에 맞는 feature들만 학습하도록 하여 성능을 떨어뜨린다.
Early Stopping