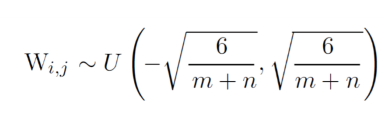DL06
DNN
Regularization
Parameter regularization
Parameter tying
- 같은 task를 수행하는 두 모델을 같은 데이터로 학습할 때 서로 비슷한 분포를 가진다. 두 모델의 차를 loss function에 넣음으로써 규제하면서 학습한다.
Parameter sharing
- 여러 모델이 같은 parameter를 공유한다.
Pruning
- Network 모델 구축이 끝난 후 일정 비율의 weight을 0으로 만든다. 그리고 그 weight가 없다고 가정하고 다시 학습을 한다.
- 이런 과정을 계속해서 그 비율을 늘려가면서 반복하여 일정 정확도보다 떨어지지 않는 수준에서 연산 수를 줄일 수 있다. 줄여도 충분한 성능이 나온다.
Dropout
- 학습 시 특정 노드의 출력값을 0으로 만들어버린다.
- dropout ratio : 꺼버릴 weight의 비율
Pruning vs Dropout
- pruning은 학습이 모두 끝난 후 어떤 특정노드들을 없애버려도 성능이 나온다면 해당 노드들을 없애서 연산량을 줄이려는 목적이다.
- dropout은 학습과정에서 regularization을 위해서 일정 노드들을 꺼버리는 것이다.
Adversarial training
- 사람이 구별할 수 없는 데이터를 섞어서 훈련시키는 방법
- 잘못된 데이터를 추가해줌으로서 일반화 성능을 높여준다.
- 데이터가 도난되었을 시 해당 데이터를 이용하여 학습을 하는 행위로부터 데이터를 지키기 위하여 쓰인다.
Bagging
- training data를 random sampling하여 여러 개의 모델을 학습하여 그 결괏값을 이용하여 학습하는 방법
- bagging을 이용하여 variance를 낮출 수 있다.
Optimization Strategies
- 더 좋은 local minimum을 잘 찾게 해주는 방법 => 거의 불가능
- Gradient Descent를 좀 더 빨리할 수 있는 방법
- 한 번 update 할 때 연산량을 줄인다.
- Step 수를 낮춘다.
Stochastic Gradient Descent
- 하나의 데이터만을 이용하여 weight을 업데이터 해준다. 한 epoch의 연산량이 적다.
- Batch : 전체 데이터
- Online : 하나의 데이터
- Minibatch : batch와 online의 중간 방법, 각 epoch마다 데이터를 잘 섞어줘야한다.
NN 최적화의 도전과제
ill-conditioning
- condition number : input값의 변화에 따라서 output값이 얼마나 변하는가, 값이 높으면 input의 변화에 매우 민감함.
- ill-conditioned : condition number가 매우 높음
Local Minima
- DNN에서 global minima를 찾는 것은 불가능하다.
- 하지만 local minima만으로도 충분히 좋은 성능을 낼 수 있다.
Saddle points and Cliffs
- Saddle point: 특정 차원에서는 local minimum지만 다른차원에서 보면 local minimum이 아닌 경우
- Gradient Cliff: loss function의 형태가 절벽형태이기에 절벽부분에서의 gradient가 너무 커서 너무 많이 weight를 업데이트하는 문제이다. gradient의 크기를 어느정도로 제한하는 gradient cliffing으로 해결할 수 있다.
Long-term dependencies
- eigenvalue decomposition을 했을 때 eigenvalue가 너무 커서 gradient exploding 또는 vanishing이 발생할 수 있다.
Batch Normalization
- mini batch weighted sum에 대해서 normalization을 해준다. => 적절한 평균과 분산을 가지도록 적절한 방향으로 이동시켜준다.
- 모든 layer마다 분포 자체를 정규 분포화 해준다.
- 안정적으로 학습되고 분포의 불균형이 생기지 않도록 조절해준다.
Transfer Learning
- 이미 학습이 완료된 모델에 일부를 다시 학습함으로써 학습의 부담을 줄여준다.
Basic Algorithms
Stochastic Gradient Descent 개선 방안
- learning rate decay rule을 적용하여 learning rate을 조절한다.
- momentum을 이용하여 최적화 direction을 조절한다.
AdaGrad
- 누적된 Gradient를 가지고 learning rate을 조절해주는 방법, gradient의 방향이 일정하다면 η을 줄이고 gradient의 방향이 계속해서 바뀌면 η을 키운다.
RMSProp
- learning rate에 일정 비율의 decay를 적용하여 그 변동성을 줄여주는 최적화 방법
Adam
- learning rate와 기울기의 방향인 Momentum을 같이 고려한 최적화 방법
Parameter Initialization Strategies
Parameter Initialization
- 어떤 적당한 분포를 가지면서 학습에 방해가 되지 않게하는 초기값을 찾는 최적화 방법
- 초기 파라미터들이 모두 다른 값이어야 한다.
- symmetry가 성립되면 학습이 의미가 없다.
Heuristic
- 사람의 경험에 의존하여 random하게 생성한다.
Glorot initialization