Dataanalysis1
DataAnalysis1
1. 데이터 분석 개요
-
Course meterials
-
Prerequisite
- Python3
- 선형대수
- 확률 및 통계
-
데이터 분류
- Structured or unstructured
- i.i.d. data or non-i.i.d. data (*i.i.d.: independent and identically distributed)
- Vectorial or non-vectorial data
- Labeled or unlabeled data
- Images, text, languages, time series, graphs, and so on
-
상관 분석(Correlation Analysis)
- 두 연속형 변수 x와 y사이 상관관계의 정도를 확인하는 것, 인과관계는 알 수 없음.
- 관련성을 파악하는 지표로 상관 계수(Correlation coefficient)를 파악
- 상관 분석 과정
- 산점도(scatter) 두 변수 상관 파악
- 상관계수 확인
- 의사결정
-
회귀 분석(Regressiong Analysis)
- 두 연속형 변수 x(독립변수)와 y(종속변수)를 인과관계로 설명할 수 있음.
- 데이터 x에 대한 결과 y를 통해 둘 사이의 함수 f(x)를 학습
-
분류(Classification)
-
군집화(Clustering)
- 데이터 사이의 숨겨진 구조를 밝혀 비슷한 데이터들을 군집화
-
Machine learning
- 지도 학습(Supervised learning)
- 비지도 학습(Unsupervised learning)
- 준지도 학습(Semi-supervised learning)
- 강화 학습(Reinforcement learning)
-
모델 평가
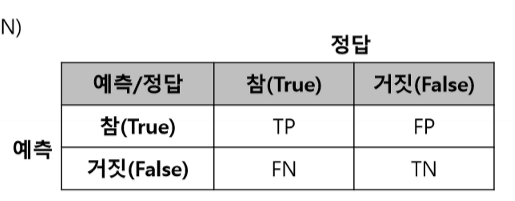
- 데이터 분석 모델을 평가하는 요소로 얼마나 정확하게 예측한 결과와 실제 정답이 일치하는지 검증하는 기법들
- 정확도(accuracy) : (TP+TN) / (TP+FN+FP+FN)
- 정밀도(precision) : TP / (TP+FP)
- 재현율(recall) : TP / (TP+FN)
- ROC(Receiver Operating Characteristic)
- y축에 TP, x축에 FP 수치를 배치해 두 수치의 균형을 살펴보는 머신러닝 평가를 위한 시각화 모델
- 커브 아래 면적인 AUC(Area Under Curve)가 1에 가까워질수록 모델 Y를 예측하는 정확도가 높은 모델
- 데이터 분석 모델을 평가하는 요소로 얼마나 정확하게 예측한 결과와 실제 정답이 일치하는지 검증하는 기법들
2. 데이터 전처리 - 1
-
Pandas
- Numpy는 2차원 행렬 형태의 데이터를 지원하지만, 데이터 속성을 표시하는 행이나 열의 레이블을 가지고 있지 않다는 한계가 있다. 이러한 문제를 해결하기 위해 Pandas를 사용한다.
-
CSV(Comma Separacted Variables)
- 테이블 형식의 데이터를 저장하고 이동하는데 사용되는 구조화된 텍스트 파일 형식이다.
- CSV 파일은 필드를 나타내는 열과 레코드를 나타내는 행으로 구성된다.
- 데이터의 중간에 구분자가 포함되어야 한다면 따옴표를 사용하여 필드를 묶어야 한다.
- ex) ‘Gildong, Hong’이라는 데이터는 중간에 쉼표(,)가 포함되어 있다. 이러한 경우에는 구분자로 사용되는 쉼표와 구분하기 위하여 반드시 데이터를 따옴표로 감싸야 한다.
- CSV 파일의 첫 번째 레코드에는 열 제목이 포함되어 있을 수 있다.
- CSV 파일이 잠재적으로 크기가 큰 경우 한 번에 모든 레코드를 읽지 않는 것이 좋다.
- 현재 행을 읽고, 현재 행을 처리한 후에 삭제하고 다음 행을 가져오는 방식이 필요할 수 있다. 아니면 특 정한 크기만큼의 데이터를 읽어서 처리한 뒤에, 다음으로 또 그만큼의 크기를 가져오는 방식을 사용할 수 있다.
- 판다스는 데이터를 처리하고 분석하기 위한 모듈이므로 다양한 종류의 데이터 파일 형식을 지원 하지만 CSV로 저장된 데이터를 사용하는 것을 기본으로 삼는다.
-
Python에서 CSV 데이터 읽기
- 파이썬 모듈 csv는 CSV reader와 CSV writer를 제공한다. 두 객체 모두 파일 핸들을 첫 번째 매개 변수로 사용한다.
- 헤더를 제거하기 위해 next() 함수를 사용한다.
-
Python에서 CSV 데이터 추출
-
Pandas의 데이터 구조 : Series & DataFrame
| 데이터 구조 | 차원 | 설명 | |:———:|:—:|:————————————:| | Series | 1 | 레이블이 붙어있는 1차원 벡터 | | DataFrame | 2 | 행과 열로 되어있는 2차원 테이블, 각 열은 시리즈로 되어 있다. |
-
Pandas로 데이터 읽기
- Pandas 모듈은 csv 파일을 읽어들여서 데이터프레임으로 바꾸는 작업을 간단히 할 수 있다.
- csv파일은 데이터프레임으로 될 수 있도록 각 행이 같은 구조로 되어있고, 각 열은 동일한 자료형을 가진 시리즈로 되어 있어야 한다.
- csv파일에서 첫 번째 열은 인덱스로 사용하기 위해 첫 번째 열의 이름을 생략할 수 있다.
- 각 열은 서로 다른 속성 레이블을 나타낸다.
- 인덱스 번호는 판다스가 추가한 열이다.
-
인덱스와 컬럼스 객체
- 데이터 프레임에서는 인덱스와 컬럼스 객체를 정의하여 사용한다. 인덱스는 행들의 레이블이고 컬럼스는 열들의 레이블이 저장된 객체이다.
- 특정한 열만 선택하려면 대괄호 안에 열의 이름을 넣으면 된다.
- 전체 데이터 중에서 두 개의 열을 선택하는 경우 : 선택을 원하는 열의 레이블을 리스트에 넣어서 전달