Dataanalysis3
DataAnalysis3
4. Regression
-
Linear Regression
- 쌍으로 관찰된 연속형 변수들 사이의 관계에 있어서 한 변수를 원인으로 하고 다른 변수들을 결과로 하는 분석
- 독립변수와 종속변수 사이의 선형식을 구하고 그 식을 이용하여 변수값들이 주어졌을 때 종속변수의 변수값을 예측 분석하는 방법
- 독립변수의 개수에 따라 단순 선형과 다중 선형으로 구분


- e의 절댓값이나 제곱을 한 후 다 더해준다.

-
Loss function(손실 함수)
- 선형회귀식과 실제 값의 오차
- 선형회귀에서 평균제곱오차(mean square error)는 머신러닝 모델을 구축할 때 작을수록 원본과의 오차가 적은 것이므로 추측한 값의 정확성이 높다고 할 수 있음.
-
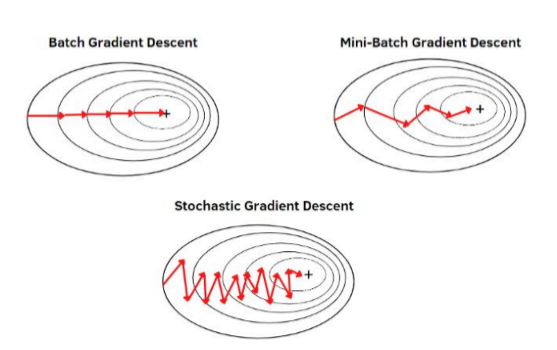
Gradient descent
- 손실 함수를 최소화하는 매개변수를 찾는 방법
- 손실 함수 값이 가장 낮은 지점을 찾아가도록 손실 함수의 기울기를 구해 최적값을 찾아가는 방법
- Batch GD / Mini-batch GD / Stochastic GD
-
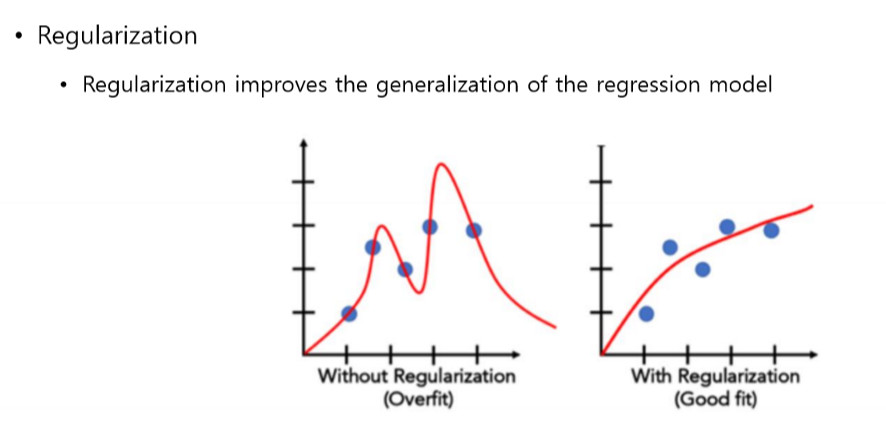
Regularization
- Overfitting : 모델이 훈련 데이터에 너무 잘 맞지만 일반성이 떨어지는 문제
- Underfitting : 모델이 너무 단순해서 데이터의 포함된 의미를 제대로 학습하지 못하는 문제
-
좋은 regression 모델이란?
- 데이터의 양
- 모델의 특징개수
- 적절한 규제
5. Classification & Clustering - 1
-
Logistic regression for classification
- 종속변수가 연속값이 아니라 비연속값이면 linear regression이 적합하지 않으며, 이 경우 logistic regression을 사용
-
Softmax regression
- Multi-class를 분류하기 위해 쓰이는 함수
-
Cross entropy
- Cross entropy는 set으로부터 발생한 이벤트를 분류하기 위해 bits(불확실성을 표현하기 위한)의 평균 숫자를 측정한다.
- 이진 분류 : sigmoid function
- 다중 분류 : softmax function
- mse x cross entropy